基于概率主题模型的物联网服务发现技术
随着物联网(IoT)设备的爆炸式增长和网络服务的日益复杂化,高效、准确地发现和匹配物联网服务已成为关键挑战。传统的基于关键字或语义描述的服务发现方法,在面对海量、异构、动态变化的物联网环境时,往往存在描述歧义、语义鸿沟和可扩展性不足等问题。概率主题模型作为一种强大的无监督机器学习技术,为物联网服务发现提供了一种新颖且有效的解决方案。
一、物联网服务发现的挑战与概率主题模型的优势
物联网环境中的服务通常由数量庞大、类型各异的设备提供,其功能描述可能简短、非结构化,且来自不同的制造商和标准体系。这使得服务发现面临以下核心挑战:
- 异构性:设备、协议、数据格式和服务描述语言的多样性。
- 动态性:设备和服务状态(如在线/离线、负载情况)频繁变化。
- 海量性:需要从数以亿计的服务中快速定位目标。
- 语义模糊性:用户需求与服务描述之间可能存在表述不一致的问题。
概率主题模型,如潜在狄利克雷分配(LDA),能够从大量文本数据(在此处即服务描述文档集合)中自动挖掘出潜在的“主题”结构。在物联网服务发现的语境下,一个“主题”可以被理解为一种服务功能或应用场景的抽象模式(例如,“家庭安防”、“环境监测”、“智能照明”)。每个服务描述可以被看作是多个主题以不同概率混合而成,每个主题则由一系列相关的关键词以一定概率分布来表征。
这种方法的优势在于:
- 超越关键字匹配:它通过潜在的语义主题来关联服务,即使服务描述和用户查询没有直接共享相同的关键词,只要它们属于相似的主题分布,就能被有效匹配。
- 处理非结构化文本:能够自动从原始的服务描述文本中提取特征,无需复杂的人工标注或本体构建。
- 降维与概括:将高维的、稀疏的词项空间映射到低维的、稠密的主题空间,便于进行高效的相似度计算和聚类分析。
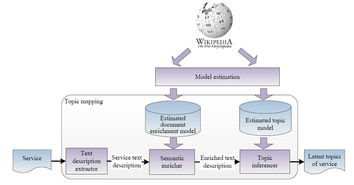
二、技术实现框架
基于概率主题模型的物联网服务发现通常遵循以下流程:
- 服务描述收集与预处理:收集物联网服务提供的自然语言描述、API文档、标签等信息,构成文本语料库。进行必要的文本清洗(去除停用词、标点)、分词和词干化/词形还原。
- 主题模型训练:将预处理后的服务描述集合输入LDA等模型进行训练。确定主题数量K(可通过经验或指标如困惑度来评估),模型将输出两个核心概率分布:
- “主题-词项”分布:每个主题下各个词项出现的概率。这揭示了每个主题的核心语义。
- “文档-主题”分布:每篇服务描述文档(即每个服务)属于各个主题的概率。这构成了服务的主题向量表示。
- 服务索引与表示:每个服务都可用其“文档-主题”概率向量(即主题混合比例)作为新的、语义化的特征表示。这个低维向量替代了原始的高维词袋向量,被存入服务索引库。
- 查询处理与匹配:当用户提交一个查询(可能是自然语言请求)时,使用相同的模型将其投射到主题空间,生成一个“查询主题向量”。然后,通过计算该查询向量与索引库中所有服务主题向量之间的相似度(如余弦相似度、KL散度),返回相似度最高的若干服务作为发现结果。
三、应用与展望
该技术可广泛应用于智能家居、工业物联网、智慧城市等场景。例如,在智能家居平台中,用户发出“我想让客厅在晚上更安全”的模糊请求,模型能将其关联到“运动检测”、“视频监控”、“灯光联动”等主题,从而推荐摄像头、人体传感器和智能灯泡的组合服务,而非仅仅匹配“安全”这个关键词。
未来发展方向包括:
- 与上下文信息结合:将设备位置、用户偏好、实时环境数据等上下文信息融入模型,实现更个性化的情境感知服务发现。
- 动态自适应模型:设计能够在线学习、适应新出现服务和概念漂移的主题模型,以应对物联网环境的动态性。
- 多模态学习:不仅处理文本描述,还能结合服务产生的时序数据、API接口模式等多模态信息进行更全面的主题挖掘。
- 与边缘计算融合:将轻量化的主题模型部署在边缘节点,实现低延迟、隐私保护的本地区域服务发现。
结论
基于概率主题模型的物联网服务发现技术,通过挖掘服务功能背后的潜在语义结构,为应对物联网环境的复杂性、海量性和异构性提供了一条有效的途径。它实现了从表层关键字匹配到深层语义关联的跨越,显著提升了服务发现的准确性和智能性。随着模型算法的不断优化和与其它技术的深度融合,它有望成为构建高效、灵活、智能的物联网生态系统的重要基石。
如若转载,请注明出处:http://www.qgtbk.com/product/23.html
更新时间:2026-06-19 09:09:20